


We’ve built so many general contractor websites – but really still love to poke around and find other amazing sites that are out there. These sites (whether our designs or other website design companies) really demonstrate some excellent principles of effective web design and general aesthetics.
(In addition to these amazing contractor website examples – included beneath them are 7 tips to getting amazing results for your construction business.)
We are a Contractor Marketing Agency – say hi!
Without further ado, 19 awesome examples of general contractor and construction websites!
Secured Roofing & Restoration (A Roofing Website We Designed – In Development)
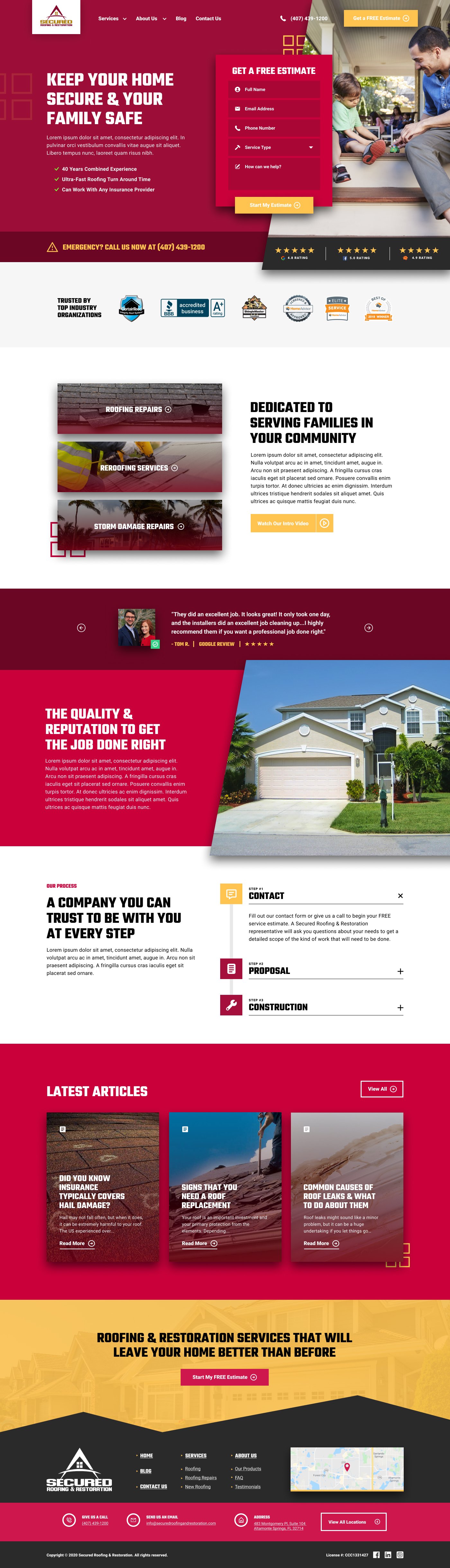
Trader Construction (A Construction Website We Designed – In Development)

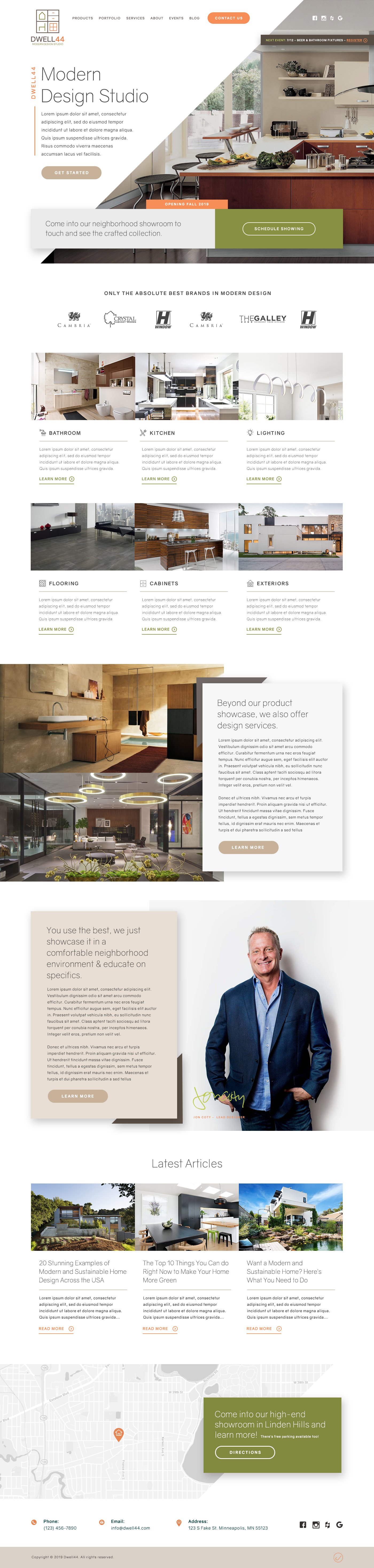
Dwell44 (A Contractor Website We Designed – In Development)
Northface Construction (A Roofing Website We Designed)

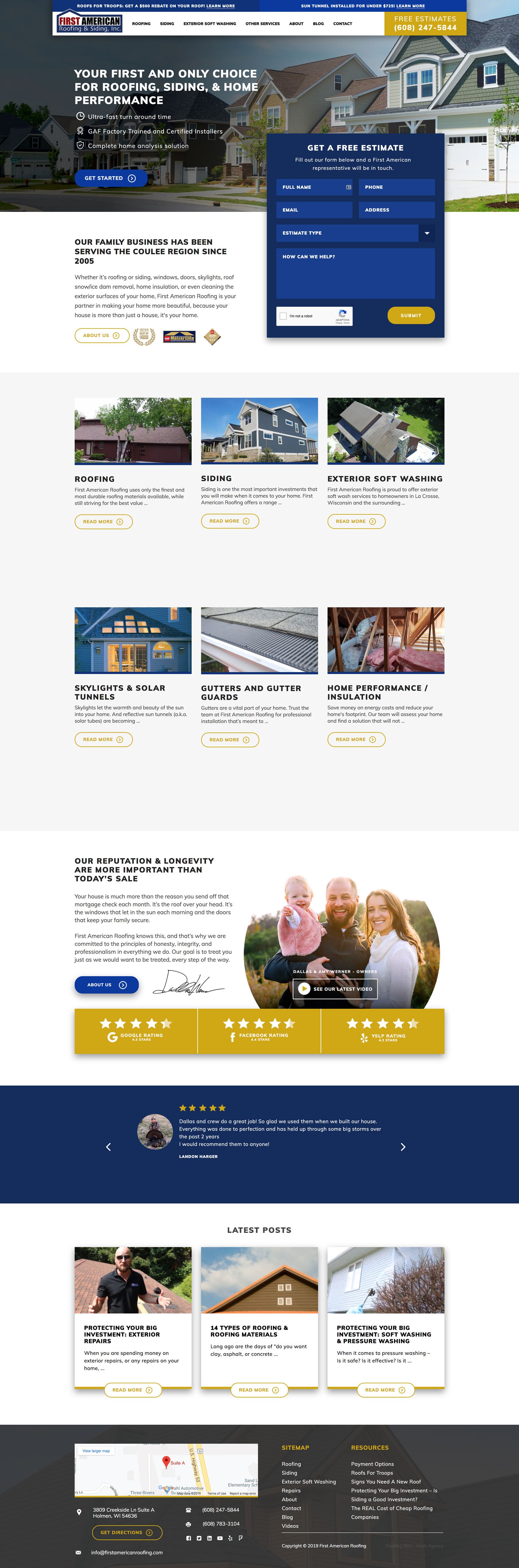
First American Roofing (A Roofing Website We Designed)
Yellowfin Roofing (A Roofing Website We Designed)

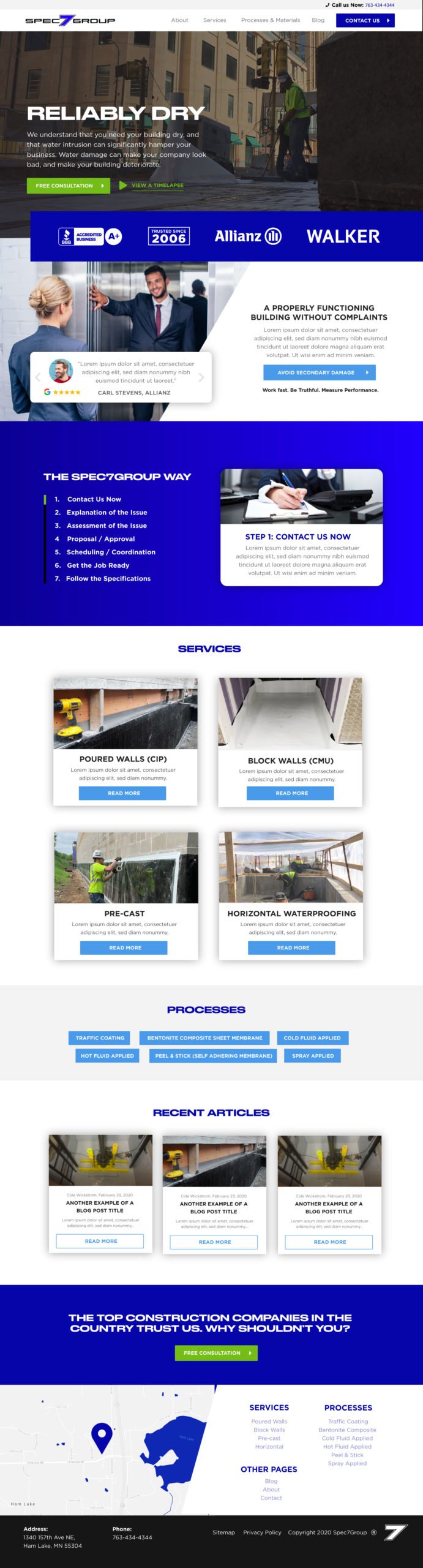
Spec7 Group (A waterproofing website we designed)
Waterproofing Contractor Websites – (Not Launched Yet)
A huge piece of this project has been simplifying core messages, showing examples, and getting trust from visitors. The first version of the site made Spec7 look like a small un-trusted company, but this new version demonstrates that they work with tons of the highest caliber construction companies on their waterproofing needs.
Why did we provide this list? We serve contractors and home service companies with marketing + web design! Check out our blog posts about Plumbing Leads, Electrician Leads, Roofing Leads, HVAC Leads, Construction Leads, Remodeling Leads and our Plumbing SEO, Electrician SEO, Roofing SEO, Contractor SEO, Remodeling SEO, and HVAC SEO services!
Puustelli – Construction Materials (Custom Scandinavian Cabinets) Website Design
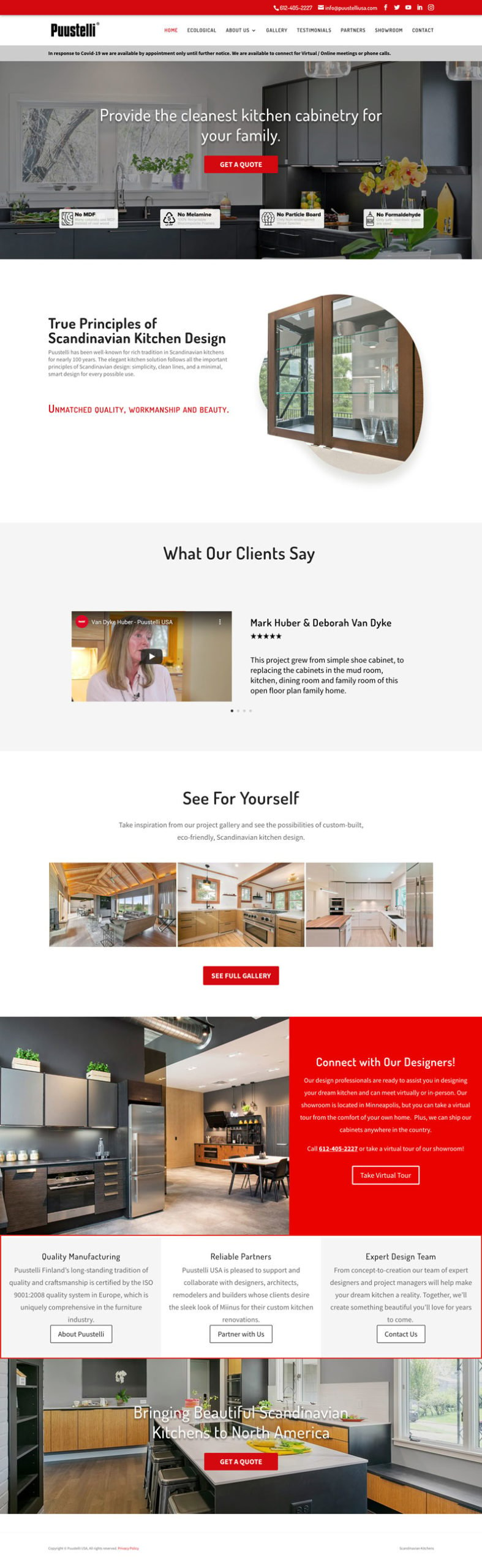
Adorned Homes (A Real Estate & Renovation Site We Designed)
Realtor and Renovation Company Web Design we designed – http://adornedhomes.com
This renovation/design-focused realtor was a client of mine, and we did our best to take the absolute best of the best photographs they had from their interior decoration and design work and make them central to the site. Good photos and good fonts are half the battle when making a website feel high end.
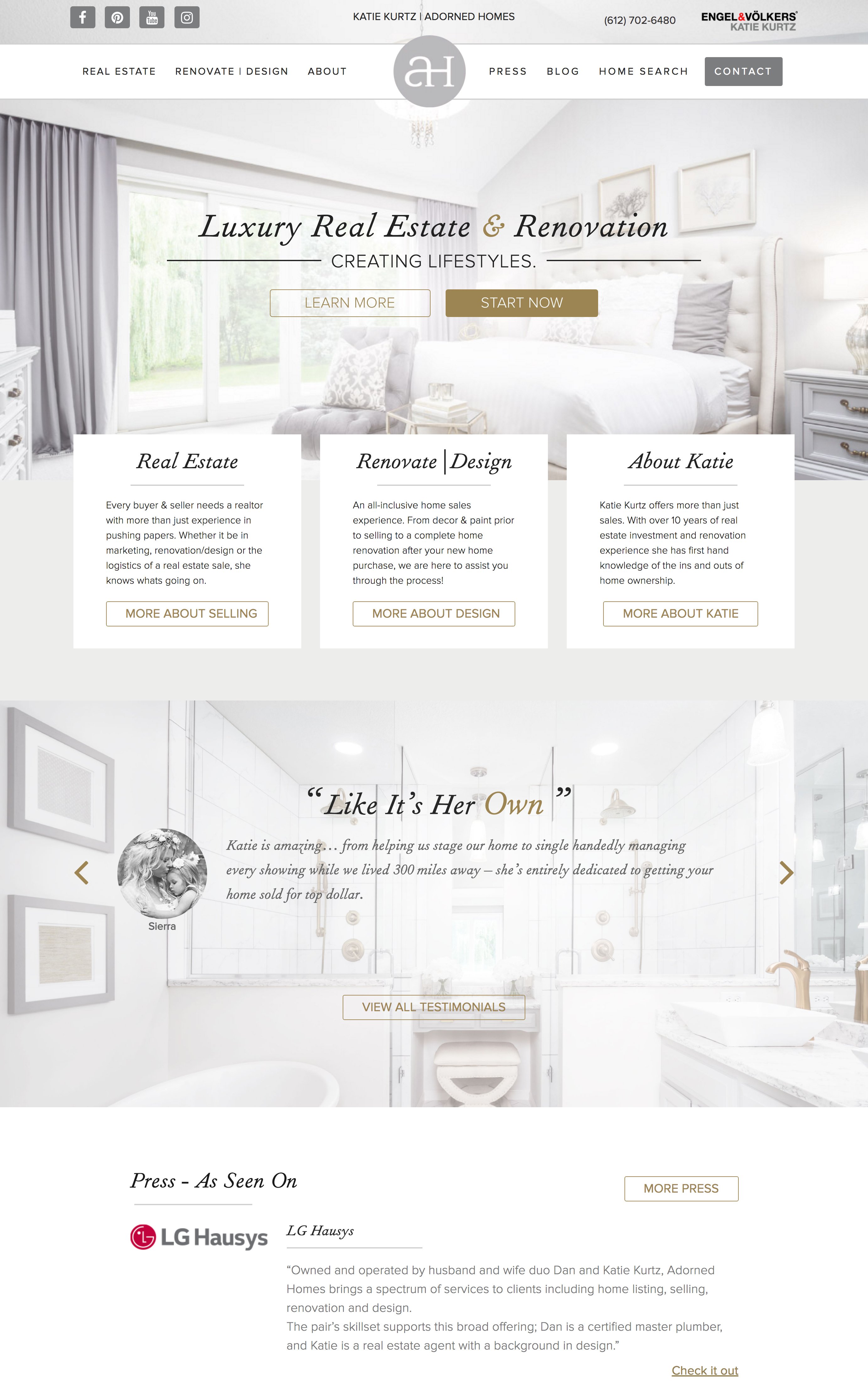
Schaefco (A Multi-family Construction Company Website We Designed)
Commercial / Multi-family Construction Company – (Still in development)
Commercial construction company website design, and multi-family company website design are not outside of our wheelhouse. In this case, this site is being built to showcase the area and the high-end details that are going into the construction of these properties. Our construction website design process goes into detail on who the ideal customer is, and in this case – the ideal customer wants everything taken care of, and in some cases, this is their 2nd or 3rd home. For that reason we built the structure of the site to amplify aspects of the condo’s to amplify elements that would help them feel ‘taken care of.’
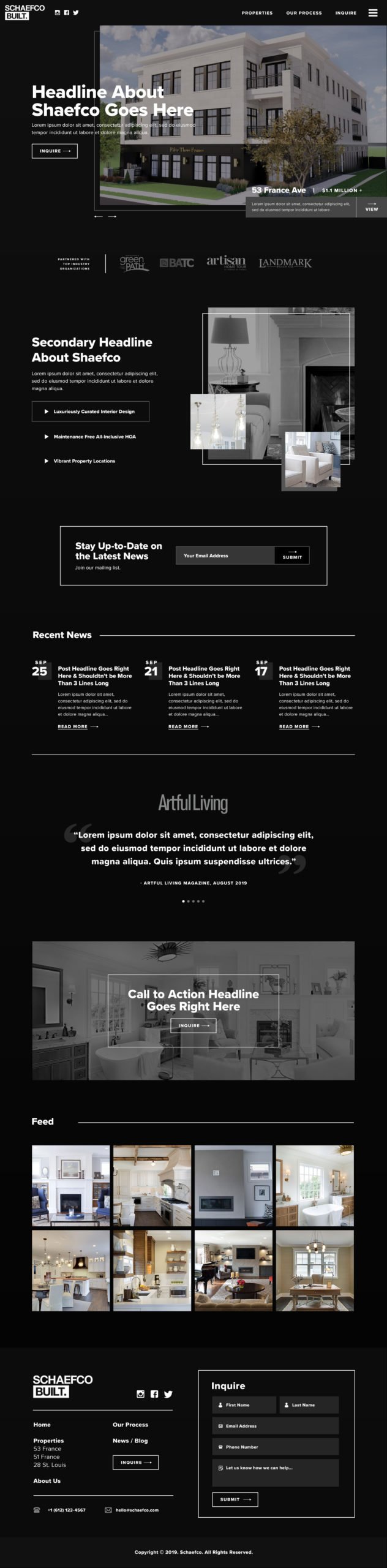
Treasured Spaces (A Contractor Site We Designed)
Custom Home Builder Web Design we designed – https://treasuredspacesinc.com
Treasured Spaces is a client of ours at Hook Agency and we not only branded them (with the demographics of the 35-55-year-old housewife in search of an upgrade or renovation), but we created this sharp site that gives a ton of information for people looking for niche residential home building or remodeling project. From the 700+ words of information provided about basement remodeling, or the visual outline of the process from design to execution – we facilitate the prospective customer’s learning process and give Google what it wants and helped get Treasured Spaces major increases in rankings for the services they offer. If you’re curious, learn more about how we help our clients get more search engine traffic and increase revenue from digital leads 200%+ – check out our Construction SEO / Contractor SEO Services.

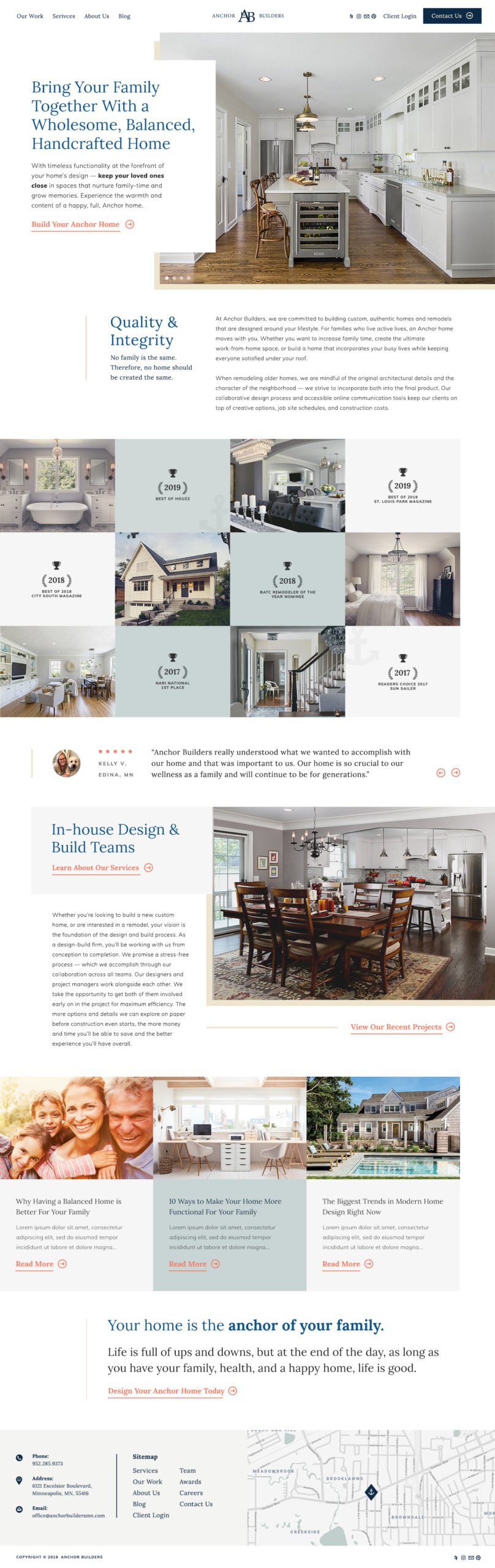
Anchor Builders (A Construction Company Site We Designed)
Construction Website Design – Being built now
This site was built from the very beginning with a heavier emphasis on the headlines, as we started with the copywriting first. We identified the ideal customers of this company as folks who cared about a healthy and wholesome lifestyle and their kids. For that reason, we drew out those aspects in the wording of things, and actually identified a few headlines that could be used in other marketing materials as well. We were particularly proud of “The Home is The Anchor of Your Family,” and some of the headlines that make this high-end, white-space infused construction company website look phenomenal.
Alpine Asphalt (An Asphalt Site We Designed)
Asphalt Company Web Design
Alpine Asphalt came to us with the simple request to modernize its asphalt company website design. I’ve had a lot of success helping contractors get their websites looking professional, so I jumped at the chance. In the end, we came out with a site that showcases their positive reviews all over Google, Facebook, and Angie’s List – and provided the right information to customers so that they could get started.

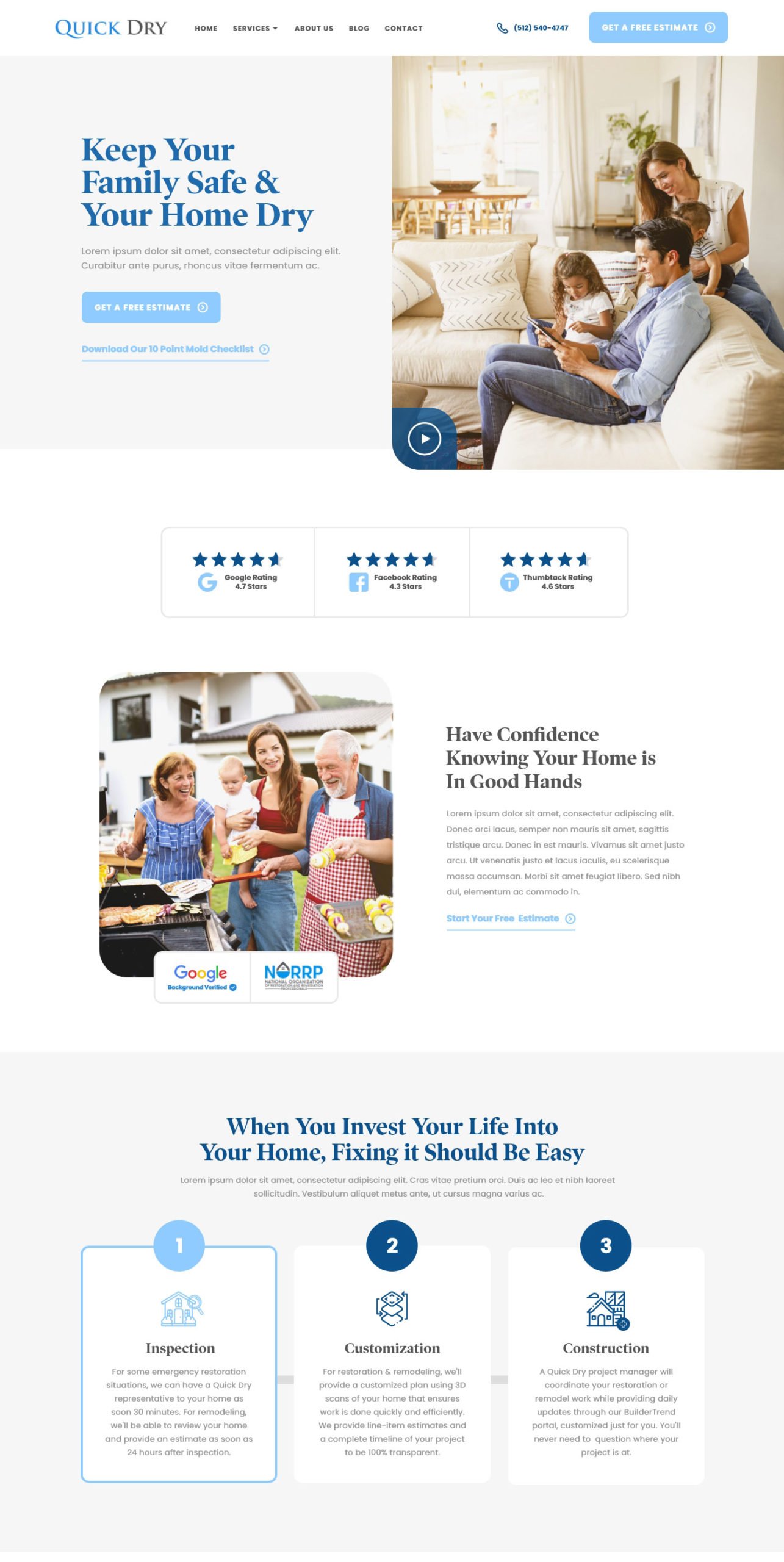
QuickDry Austin (A water mitigation website we designed)
Water mitigation and remodeling websites – (Still in progress)
QuickDry needed a website that represented them well to ideal customers and we are currently working through this design process with them. We identified their ideal customers, the reviews and organizations that will help people trust them, and the key pieces of information people would need to make a decision. Well-Designed water mitigation or disaster recovery websites will help people imagine themselves after they’ve been helped by your company. It’s not enough to tell them how awesome you are, you want them to identify with your current customers and imagine themselves in their shoes.
B&D Masonry (A Masonry Site We Designed)
Masonry Web Design we designed – http://bdmasonry.net/
This site is currently in progress, and the filler text below shows where we are working with the business owner to get these pieces added. I’m extremely excited about the new look and how we might be able to show the professionalism and quality of work on their website that they previously haven’t. Just because you’re the best in town – doesn’t mean people can psychically find that out, they need proof, both with reviews and testimonials and other visual elements that speak to that quality and professionalism.

AT Homes Builder
Custom Home Builder Web Design – http://athomesbuilder.com/
These might be one of the weaker examples on this list, but I do like the testimonials and the page dedicated to their process on this site. The AT Home Builder website design could also have some more content built out so that Google and other search engines have more information about what they sell. I suggest at least 700 words for the home page and each of the sub-services you offer.

KTS Group
Home Design Web Design – http://ktsgrp.com/
Once again this site is a little thin on the content, but in this case, the visual aesthetic is striking. A video background shows plans being drawn and then turns into a frame and then a fleshed out building. The process demonstration feels unique and interesting and captures your attention.

Forensic Construction Consulting
Construction Consulting Web Design – http://forensicconstructionconsulting.com/
From the photography to the icons that help communicate key points, Forensic Construction Consulting’s website is really a much higher caliber than most construction contractor websites and construction industry marketing web designs in general. Clean open visuals and high contrast between the text and the background make this site stand out among its peers.

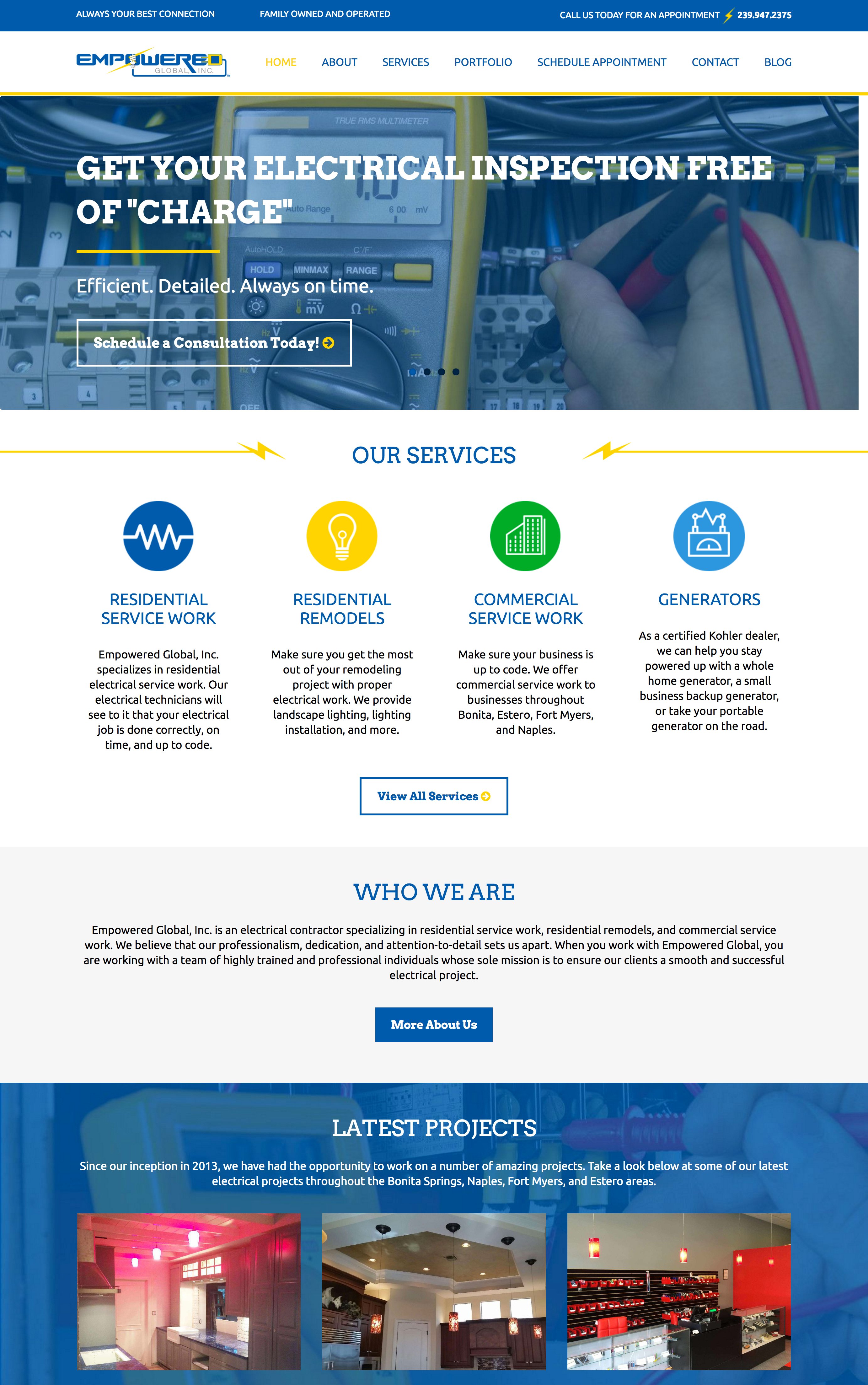
Empowered Global
Electrical Contractor Web Design – http://www.empoweredglobalinc.com/
Empowered Global might be a touch less modern than some of the other highlighted sites – but the message is clear about what they do, the phone number stands out at the top right of the design, and examples of their work are front and center and easy to get to. No matter how stylish your website is, what’s most important is the ease of use, the clarity of your message, and nudging people in the direction of the action you want them to take on your site.
I hope you enjoyed these awesome construction company, and general contractor websites – and got some ideas about how you might implement some of the things they do well on your construction industry website design. If you need any help with your construction company marketing or website design – check out our work and get a free consultation. Thanks!
7 Ways to Make a Construction Website Design Beautiful + Effective
Having worked on 15+ construction and home services websites now, I’ve learned some things I think will help other designers – and possibly the owners of these companies or marketers working on their behalf.
Imagine for a second – that it’s not only your job to make the website look pretty, and showcase the work of the company well, but it’s your job to create an emotionally persuasive story in the site – and invite people to work with the company.
At the core of every designer’s is communication – and if you need to work on that brand story with a copywriter before getting down to work on the actual visual design of the site, that may be a smart place to get started.
1. Make the visitor / ideal client the hero of your website and brand story, not the company.
Make sure to ask who their ideal customers are, and keep pushing until the scope is super tight. If they say 30-70-year-old working professionals with a 500k+ home. Say – if there were only a 5-year window for age, what age group would have the most ideal customers out of any.
The point is not to exclude people – the point is to aim.
If we aim super tightly, and really think about the psychology of a tightly defined group – then we’re more likely to appeal to people in general. Generalities and platitudes rarely are emotionally persuasive. But if you aimed at a 47-year-old mother with a husband that works ALL THE TIME and said “you have more on your plate than you thought you could ever handle – let us take remodeling off the ‘honey-do’ list, and into reality’ – imagine how that might resonate with 37-year-old men, and with 55-year-old women too!
2. Invite that ideal customer to imagine themselves experiencing the emotionally invigorating aspects of a project with the company, and the completed work both with imagery and with the copy.
This can be in simple ways, like making the big billboard photo of the website – an ideal customer of the company enjoying the benefits of the product or service.
I like to ask clients – “what’s that moment when the customer really starts to feel that they’ve made an amazing choice – going with your company? What are they doing at that time, usually? Are they looking out their window at a clean lawn, despite the fact they just saw 5 people replacing their roof, and removing all of their equipment?”
Try to get to the bottom of what those moments look like – physically, and tell that story with images as best as you can.
3. Showcase amazing work, and before and after photos.
Nothing is more persuasive than a markedly different after photo, sitting next to a before photo that looks like the ideal client’s current situation. Find ways to ask for these from the people that can get them – and invite them to make this a consistent part of their process.
4. Home-Builders create places for a portfolio of examples, that invites people to interact with it and get excited about perhaps create a similar project.
Ask the client – or leadership of the company, ‘What type of work is lucrative for you, and what type of work do you love.’
I’ve experienced a lot of construction companies say ‘we don’t need more work’, but I’ve never heard one say ‘we don’t want more ideal customers, or we can’t increase the quality of leads coming in off your site.
What do you do with all of this info? You make sure you showcase jobs like these.
What you show, is what you grow.

5. Utilize video wherever possible – particularly to give an emotionally persuasive story/introduction to the people in the company and why they care.
Make the play button inviting – and sometimes use a still from the video in the visual design / UI of the site.
6. Link to related blog posts on the individual service pages – perhaps with a ‘related posts’ section at the bottom of the page.
Nurturing visitors with related content is powerful because it both reminds them
7. Don’t be afraid of the ‘lead form’ the ‘phone number’
Think about key places that will go with the flow, to invite people to work with the company. Some people are just coming to the site for this reason, so it’s OK to lead with it, and use verbiage like ‘get started,’ ‘get a free consultation,’ or ‘get a free estimate.’
The point is that there are very few secrets when it comes to creating an effective construction company website.
Find amazing examples on Awwwards, Behance, Dribbble and Pinterest, and trust yourself.
What do these general contractor website examples have in common?
Big images, audience-focused headlines, and trust factors – these elements help your contractor website awesome.
- Big images: modern web design uses huge images of your best work, and happy customers. Don’t be shy – take up some space, people are used to scrolling vertically, the page doesn’t have to be short.
- Audience-focused headlines: Stop talking about yourself, and figure out what your ideal customers want and use that language in your headlines.
- Trust factors: You need to find ways to get people’s trust quickly, but more on that in the next section.
“We’re all, necessarily, the hero of our own story” – Franz Kafka
The one thing you need to make your local contractor website amazing:
Trust is the number one biggest key to making an effective website.
Can you help people trust your company quickly and easily?
- Real pictures of your team
- Map of your location and address
- Phone number on every page.
- Carousel of reviews and photos of reviewers
- A horizontal row of awards, certifications, places you have a high review average.
5 easy construction website design ideas you can implement now
- Consider having a ‘get a quote’ or ‘start the conversation’ form at the top of each selling page.
- Get photos or videos of your ideal customers smiling in front of a completed project (and in the case of video) telling their story. Incorporate on every selling page.
- Have an icon or photo focused list right below the ‘billboard’ / top section of the website, so that people know the top services of the company quickly.
- Have an FAQ section on every selling page – using ‘show/hides’ addressing common questions that come up in the sales process.
- Make sure there is a contact or ‘get a quote’ button top right on every page to nudge visitors from around the site to take the next step, and remind them of the purpose of the website.
3 Construction website builders if your just starting out
It pains me to say this – but there are 3 options for ‘website builders’ that will work for a construction company.
Although none of these are ideal (we love WordPress for real, and substantial reasons), you can definitely get started with a Wix website or Squarespace, start blogging, and get links back to your website (huge for Google visibility.)
Before you do any of this – Google My Business is the biggest weapon for local businesses that doesn’t even require you to have a website.
- Squarespace–for photography heavy websites with simple sleek design (not great for SEO.)

- Wix – A ton of different templates, but with more options, often ends up looking unprofessional.

- Weebly– makes rolling out a mobile site primary.


Need contractor website services – we’re here for you!
We create 100% custom websites.
We design from scratch, and then we do web development on WordPress so the site is easy for you and your team to edit and add new pages.
We tend to work with companies that have tried the cheap option, and now are ready to LOOK professional, give off a persuasive impression, actually gets leads.
Where visual design – and SEO combine. We help contractors hook better leads, contact us now to get started!
Some frequently asked questions about contractor web designs:
Should I go with a template or have my site custom designed?
Often contractors who are early in their business choose to go with a templated website design, but after when they’ve been in business a few years – decide to move onto something that’s custom for their business. The ideal is that a website tells your unique story, is built around your best images, and doesn’t look like any other competitors’ sites. Beyond website design – being visible on the web is by far the most important part of marketing yourself online.
What are the most important parts of having an effective website?
Search engine optimization should be considered during your website design. How can you make sure your most lucrative services will be central to the website and get the right amount of content/word count (a key ranking factor on Google.) Having your contact information central, being ideal customer-focused in your headlines, making sure your images are compelling, and making sure organizations/awards/testimonials give credibility and trust and help website visitors take the next step.
How do you do construction marketing?
Companies should be aggressive about their marketing for more reasons than just getting new clients. Good marketing makes your current employees proud, it makes future ‘A Players’ easier to attract, and it makes your current customers feel like they made a great decision. For that reason – you should wrap your trucks, use yard signs or signage on job sites, be involved in local events, and certainly, you should be doing Search Engine Optimization, some paid advertisement as appropriate and social media marketing at least around your culture and/or before and after’s. What you focus on most is going to depend on your market, and what your key goals are – but these are a few ways to get started. The website, and creating happy customers to refer new business are central to everything you’ll do in marketing.
How do most contractors get new clients?
The first way is word of mouth and referrals – from there, growing construction companies will want to scale into two main forms of marketing. Brand marketing, and lead generation marketing. It really depends on the size that you want your company to grow and how much of a reputation you already have. We believe content marketing and SEO are an easy way for growth-focused companies to get more out of their marketing dollars, and we help them save time and get leads with our aggressive approach. If you need SEO and premium professional web design – we’re a great option.
Why is SEO important during a website design project?
Most web design companies have a hard time creating websites that demonstrate an appropriate understanding of SEO. They cut corners because it’s easier to let the client dictate how a project should go rather than being a professional and making strong suggestions that will positively affect the mileage you get from your website. SEO is important during the build of contractor websites because you need to make strong suggestions for where to include more text (Google has to be able to read and understand what a page is about), and in the development process, there are all kinds of decisions being made that will affect the way Google indexes a page. Make sure you partner with a company that understands how Google reads the internet, not just a company that can make your website look pretty.
How much should I spend on a contractor website?
It really depends on what you feel a website could make you. A ‘business card’ style website might net a 3 million dollar construction company 10 leads a month – but what if a website could drive 20-30 leads a month instead? This is the kind of opportunity that drives smart contractors to seriously invest in their website design. If you’re the type of contractor who’s committed to getting more and better leads with a website that reflects your premium services – send us a message now for a free consultation.








