There are certain cases where you shouldn’t be doing A/B Testing. Don’t do A/B testing if you only sell two products a month, or only have two conversions a month. Any conclusions you come to under that circumstance will surely be misleading. Also, don’t test too many variations of your design for anyone page or product page template at once even if you have a bigger site. It’s better to do simple A/B testing, you’ll likely get a much stronger conclusion and be able to make serious changes more quickly.

Now where and when do I want to end an A/B Test?
When I reach statistical significance? Not so fast hotshot. If you have bigger wins you could possibly make the change permanent (anything over 50%,) but otherwise, you should wait for the right sample size for your situation. Peep Leja suggests 250-350 conversions at least before making a change based on data unless you have a giant site.
- Wait for 250-250 conversions or at least a representative amount of traffic
- Wait at least 2 to 3 weeks to make a permanent change.
- Wait for bigger wins (50% or more) if you want to make a change based on lower traffic
For myself I like to implement A/B Tests on my homepage even though I don’t have an insane amount of traffic. So to me what this is advising me to do is to only implement if I’ve waited a month, with a strong swing in conversions (I can expect at most 15 at this point in my business) and so I need to weigh my experience with best practices and not get too excited about any wins.
The dilemma is getting a false positive by ending quickly when the A/B testing tool suggests there is a clear winner with statistical significance
Example
For bigger clients it’s a lot easier to see big changes and get excited, but it’s important not to check stats too often as I can get seduced by numbers and get thrown off by big swings. For me I wait at least a week after the software I use reaches statistical significance and make sure that the amount of conversions is a representative sample size.
The company SumAll did a test with Optimizely and found that running their home page against the exact same version of their home page gave them a +18.1% improvement. Their business model demands that they don’t make big shifts in their website without a real, substantial assurance that they aren’t making bad decision, so this made them question changes they had been making with Optimizely.
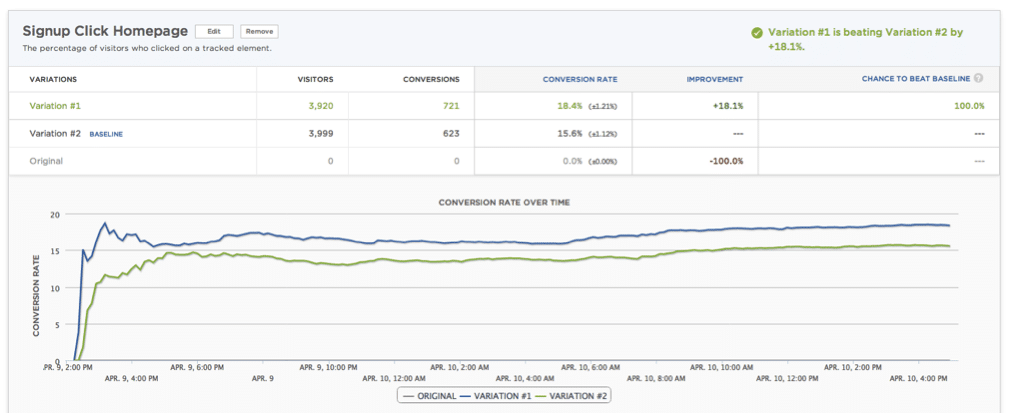
The writer of their blog post about this phenomenon explained that it’s because of the difference between ‘one-tail’ and ‘two-tail’ tests; one tail only considers the possibility for improvement with the new variation, and two tail takes more visitors and considers the possibility the original is better.
But because I’ve experienced tests that came out in clear favor of the original, I’m not sure this isn’t just a ploy of an Optimizely competitor being kind of shady about they way they promote their product. The truth is that Optimizely is actually running two ‘one tail’ tests simultaneously. The TLDR; here is that both of these posts end suggestion is simply to run your test longer – past the point where your tool tells you to stop.
Make sure that the sample size you choose is representative of your normal traffic
If you have a product that has a major upswing in traffic during the holidays, for instance, you can get a great amount of data at once, but the most accurate data will likely be in a plateau, not in a wild swing. Unless of course if your products are actually sold mostly only around a holiday, then you’re representative normal traffic would be smack dab in the middle of that busy season, and ideally throughout a good portion of it to level off any sharp edges or unrealistic spikes in traffic.

If you’re interested in Statistical significance in A/B Testing, you should definitely watch this video at some point. I talk about some of the key points below.
Doug Bowman left his post as chief designer as Google after being asked to test 41 shades of blue. He felt that data should drive design only to a certain point. He felt that there was way more important aspects of design that are more important than his boss Marissa Mayer’s ‘data-driven to a fault’ approach. According to the video when there are things like 41 shades of blue you will almost always get a false positive based on the problems with the math at that level.
[bctt tweet=”In the case of Google’s 41 shades of blue, even at 95% confidence level the chance of a false positive is 88%.” via=”no”]
So the power of A/B testing is limited in certain scenario’s and I think the key here is just that design is a multi-faceted discipline that also requires hard work and taste to create something truly exquisite. It really isn’t something that can be formed solely by a billion statistical equations, there has to be a theory of designer and implementation and refinement based on that theory.
Test theories, not headlines
A theory example – “I think that when the customer get to this point– when they get to the pricing page, they’re ready for a hard sell.” In the example Jason Cohen suggests that you’re still changing the headline – perhaps to “Buy Now”, and perhaps removing a sidebar to focus the visitor in, but the point is that these changes are based on psychological principle, empathy, and understanding of context rather than simply tinkering with verbiage.
A couple more theories from the video – “I think people that come from this traffic source would be interested in seeing X next.” “People who have just searched for security, would like to see testimonials about security, or a list of features on security.” “I think at this point a person would love to chat with a human.” – Testing whether the chat pops up at 30 seconds or a minute and seeing how that affects conversions perhaps. Jason says not to just spitball but to test hard theories, such as “I think that once they are on the pricing page, they are ready to talk to a person who might gently encourage them to proceed.”
“We think that people that are presented with a video instead of just text on the home page, will be more likely to engage, look at more pages, and to buy.” – In testing this scenario Jason says that people weren’t and that they were wrong. People were more likely to spend time on the site, but only the exact amount they spent watching the movie.
By having a very strong theory from the beginning, it always Jason and his team to challenge their other assumptions about why customers engage and get’s their ideas rolling on ways to improve the site.
So simply put the quick version of this article is; “Make strong explicit theories based on your customer needs, and then when you test wait for a representative sample size or a couple weeks past when your tool says there is statistical significance to stop your A/B Test.” Thank you for reading!